
7 MIN READ/Aug 14, 2025

AI’s great. Until it’s not. You can have the smartest algorithms, the best engineers, even a fat budget and still hit a wall because your data just isn’t good enough. We’ve seen it happen. Repeatedly.
The problem? Real-world data is messy. Or scarce. Or locked up behind privacy rules that make Fort Knox look like a lemonade stand. And when you do get your hands on it, it’s often biased, incomplete, or costs you a small fortune to annotate.
That’s usually the point where synthetic data for AI stops being a “cool concept” and starts being your oxygen supply. You can generate synthetic data that acts just like the real stuff, same quirks, same patterns, without all the legal knots and logistical headaches. And if you outsource data annotation to folks who live in that world day in, day out, suddenly your AI project isn’t crawling anymore. It’s moving.
In this blog, we are going to walk you through how to generate synthetic data, why it works so well, and how the right outsourcing partner can turn the whole process from a grind into something almost, painless.
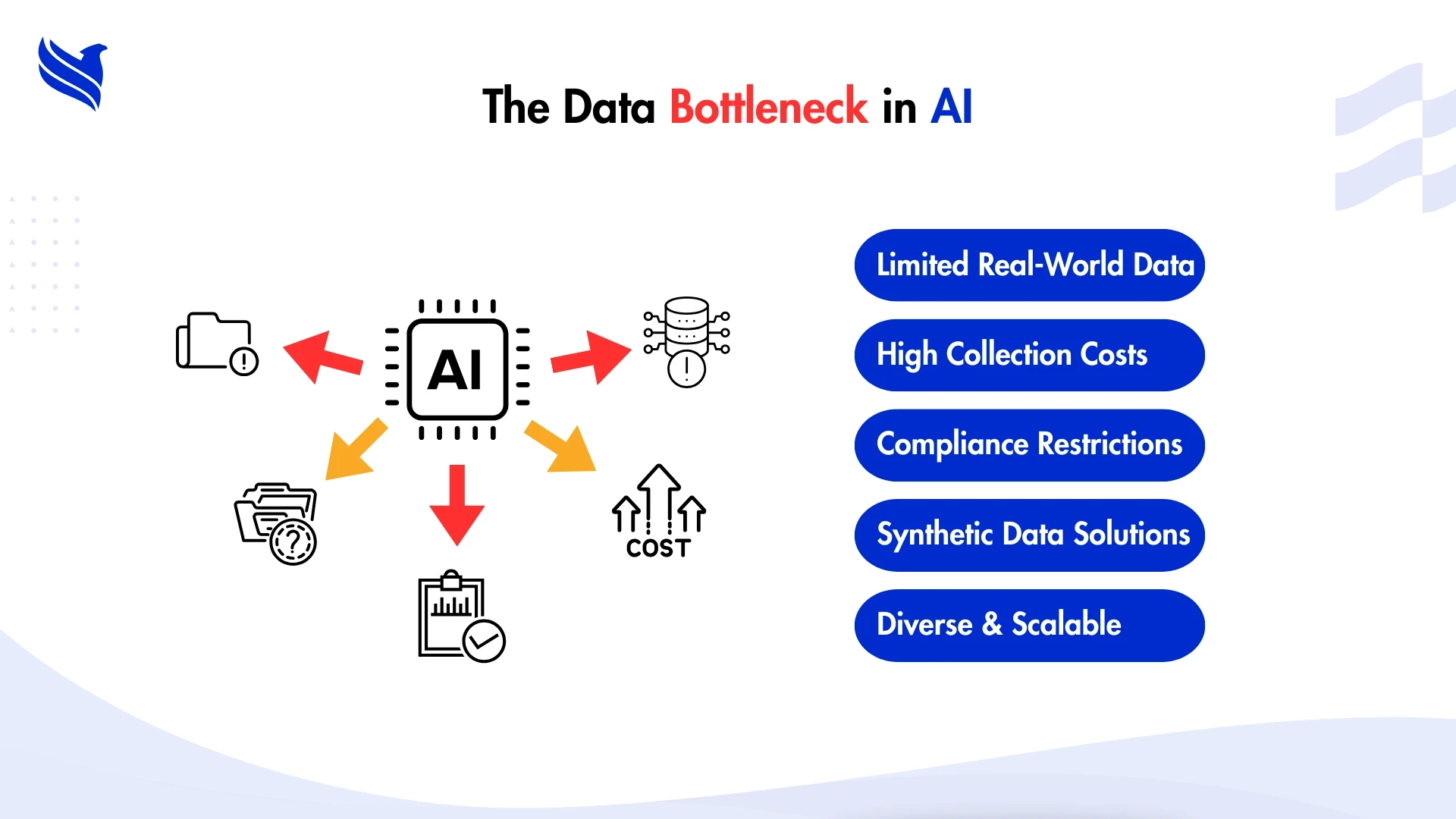
Here’s the truth: most AI teams don’t stall because of bad code. They stall because the data they do have is either:
Sound familiar?
Synthetic data changes the equation. You can scale faster, cover rare edge cases, and dodge privacy landmines. It’s why industries from healthcare to automotive are leaning on it heavily. And as this guide on 5 business problems synthetic data solves that real data can’t explains, sometimes synthetic isn’t just the better choice, it’s the only viable one.
Short answer? Absolutely. Long answer? It’s already everywhere, whether people realize it or not.
This isn’t some fringe experiment happening in a dimly lit lab with PhDs huddled over whiteboards. It’s baked into the workflows of some of the biggest, most data-hungry industries on the planet.
Take self-driving cars. They don’t just gather data from real-world drives; they run millions of simulated crash scenarios, from icy backroads in Alaska to sudden pedestrian crossings in New Delhi, because waiting to see those events in real life would take decades.
Or banks. They feed their fraud detection systems fake-but-perfectly-realistic transaction histories, complete with unusual spending spikes and geographic oddities, so models learn to flag the weird stuff without ever touching real customer data.
Retailers? They’re using artificially generated shopping data to stress-test demand forecasts for holiday seasons, product launches, and even panic-buying scenarios, things they can’t afford to get wrong in the real world.
The thing is, AI doesn’t have a loyalty card for “real” data. It doesn’t care if it’s synthetic or authentic, it cares about three things: quality, coverage, and relevance. And on those fronts, synthetic often wins. You can tweak variables until the dataset is balanced, inject rare scenarios on purpose, and recreate situations that reality would never hand you on a silver platter.
So if you’ve been wondering, “does AI use synthetic data?” the answer isn’t just yes, it’s yes, right now, in production, and it’s only going to grow. The companies who get good at generating and using it are the ones who’ll ship faster, scale smoother, and stay ahead while others wait around for their “perfect” real-world dataset to arrive.
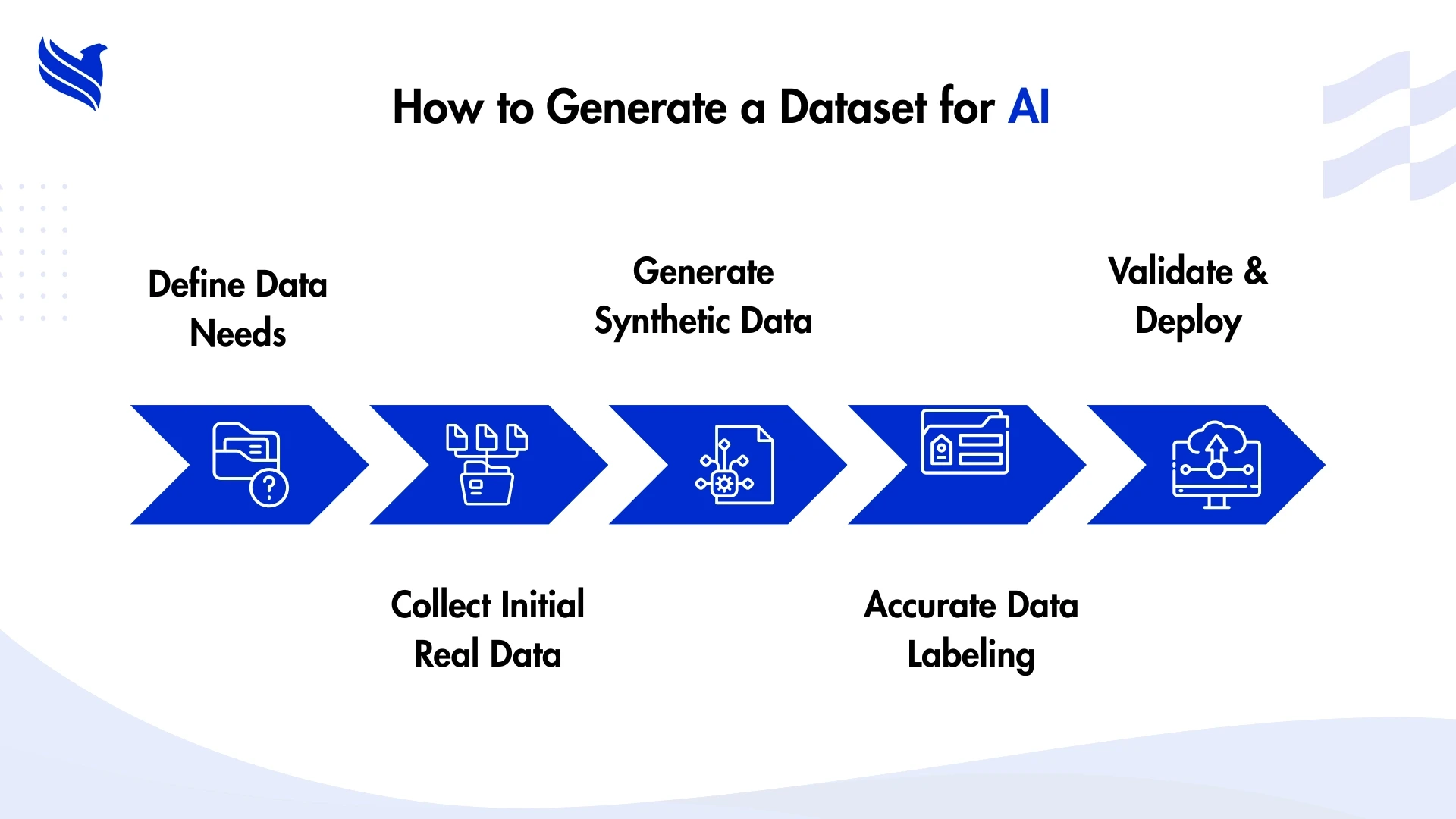
Before you even think about how to generate a dataset for AI, ask yourself: what exactly am I solving?
Not in vague terms. We mean:
Once you nail that down, your next move is finding the right mix of sources:
Start small. Build, test, tweak. Then scale. That’s how you keep your dataset useful instead of bloated and brittle.
Here’s where most guides get too sterile. In the real world, you’ll mix methods depending on your problem.
You set the parameters, the machine spits out variations. Think generating fake financial transactions with different amounts, currencies, and timestamps.
Used in robotics, gaming, autonomous driving. You build a virtual world and let your AI roam. Every interaction gets logged and labeled.
GANs, diffusion models, you’ve seen the headlines about AI creating “photorealistic” images or voices. This is that, but with a specific purpose.
You take real data and mutate it, flip images, add noise to audio, rephrase text, so your model learns to handle variations.
The trick when figuring out how to generate synthetic data for machine learning isn’t just cranking out gigabytes. It’s making sure the synthetic stuff mirrors the statistical patterns of the real world.
Validate it. Compare distributions. Train a model on it and see if it holds up. Keep a feedback loop running so you’re always adjusting the generation process.
Synthetic data is just raw material. To make it usable, you still need to clean it, annotate it, validate it, and keep it consistent. That’s a lot of work, more than most in-house teams can handle without burning out.
That’s why data labeling outsourcing is a no-brainer for a lot of companies. With the right partner, you get:
Based on this, we can clearly state that outsourcing data annotation services is critical for success in this digital age. Outsourcing frees you to focus on building models instead of babysitting spreadsheets and labeling tools.
Here’s the thing, synthetic data generation isn’t a niche hack anymore. It’s core strategy. Done right, it makes AI better, cheaper, and faster to deploy.
At FBSPL, we’ve seen clients go from “stuck in data collection hell” to “launch-ready” just by combining synthetic data with top-tier annotation. Our AI proposal generator tool is proof, it pulls from high-quality, carefully prepared datasets to help businesses respond faster and with more precision.
If your AI project is moving slower than you’d like, or worse, not moving at all, it might not be your tech stack. It might be your data.
Reach out to FBSPL and let’s get you the kind of dataset your AI deserves.
Insights and analysis from our industry experts.



