
10 MIN READ/Jul 31, 2025

Data is meant to guide decisions, fuel innovation, and sharpen your edge. But more often than not, it slows teams down. You spend weeks or months gathering, cleaning, labeling, only to realize the dataset is flawed. It’s missing context, riddled with bias, or too sensitive to use without legal red tape. And the risks? They’re real, privacy violations, regulatory heat, even exposing internal strategies. That’s where synthetic data steps in, not as hype, but as a practical answer to problems real data can’t solve.
Now before you raise your eyebrow, understand this: synthetic data isn’t a placeholder or a ‘simulation.’ It’s the data you wish you had, precise, controlled, and custom-fit to your models and goals. Businesses sitting on sensitive, sparse, or heavily-regulated datasets are using it to accelerate product dev, train AI, and dodge legal landmines. And yes, outsourcing the generation of synthetic data is not just a cost-saver, it’s often the only practical route if your internal teams don’t have the bandwidth or deep tech expertise.
In this blog, we break down what synthetic data really is (minus the textbook jargon), how it helps machine learning teams run faster and smarter, and five specific problems it solves better than any amount of real-world data ever could. You’ll also see how outsourcing it can take the load off your team while keeping your AI efforts sharp and compliant.
Let’s cut through the usual noise. Synthetic data isn’t some vague tech fantasy; it’s data that’s been created, not collected. Built using algorithms and models (like GANs, if you’re deep in the weeds), synthetic data mirrors the patterns, relationships, and logic of real data, just without the actual, sensitive details.
No names, no emails, no privacy concerns. Just the structure and behavior of real-world information, reimagined from scratch.
Here’s a quick way to picture it: imagine you’re developing a self-driving car. You could send it into downtown L.A. traffic and pray nothing goes wrong. Or, you could create a virtual city with fake traffic lights, unpredictable drivers, and nasty weather, all of it realistic enough to train the car safely. That’s what synthetic data does. It lets you train, test, and stress your systems in a zero-risk sandbox.
Now, let’s be real, synthetic data isn’t flawless. Used poorly, it can skew your models, miss edge cases, or overfit on patterns that don’t matter. But when you know what you’re doing, or work with people who do, it becomes one of the smartest assets in your AI or product stack. Especially when real data is messy, sparse, or locked behind privacy regulations.
There’s a reason ‘Synthetic data for machine learning’ is trending in real engineering discussions, not just industry slideshows. It solves one of the dirtiest problems in ML development: data bottlenecks.
Here’s how it plays out:
Machine learning isn’t magic. Feed it junk, and it produces junk. Synthetic data gives teams the ability to generate training datasets with exactly the balance, variety, and edge cases they need, without having to collect years of real data.
It also shines in scenarios like:
ML models trained on well-structured synthetic data are now reaching accuracy levels on par with those trained on real-world datasets. And when you mix synthetic with real, you get even better generalization. The result? Faster iteration cycles, better performance, and fewer legal headaches.
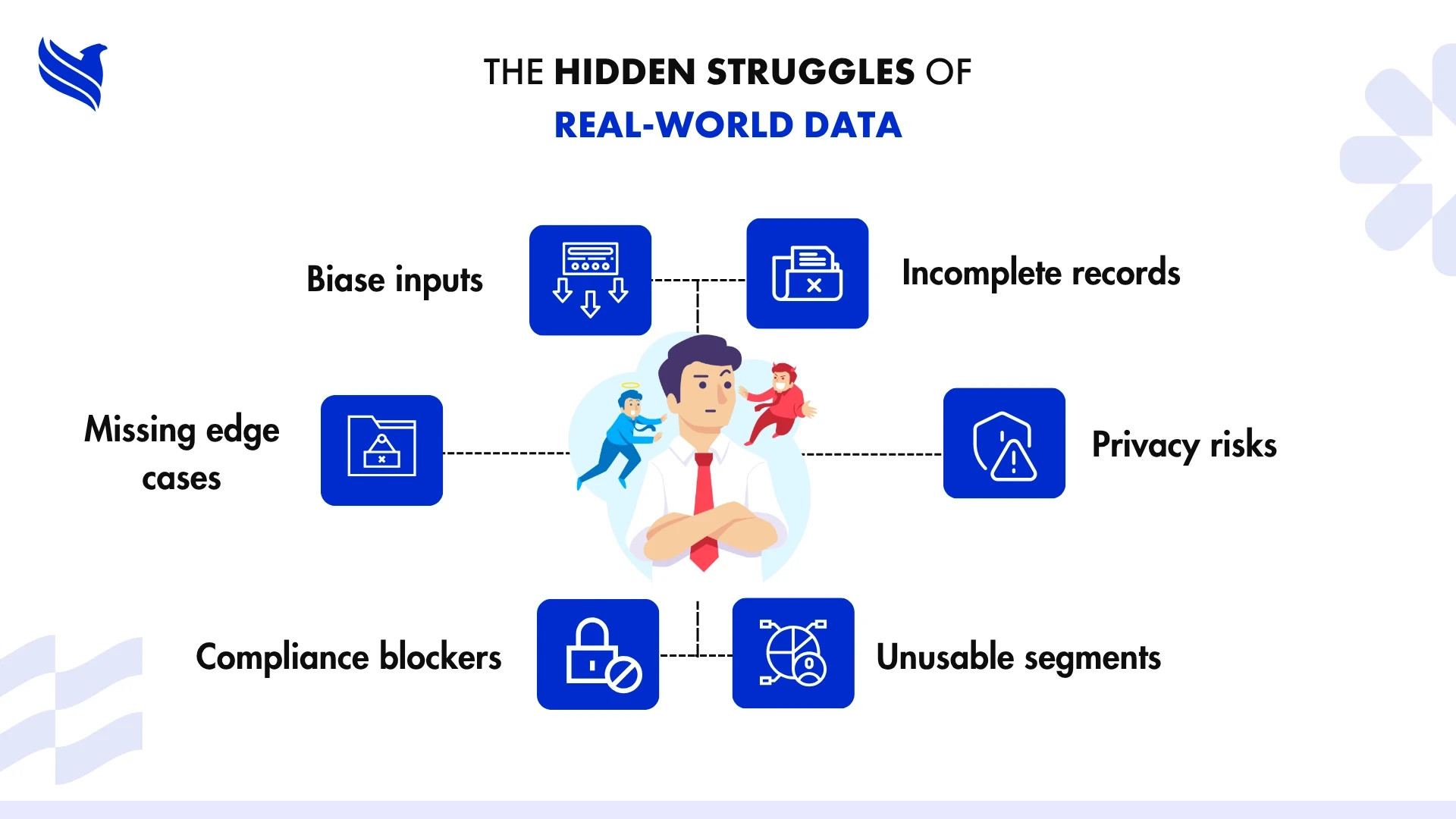
Let’s get to the point. There are problems your real data can’t fix, no matter how much of it you collect or how many hours you throw at cleaning it. Here are five of the biggest ones synthetic data handles better than anything else on the table.
When privacy is a legal minefield
If you’re working with any kind of personal data, health records, financial info, user behavior, you’re walking a fine line. Privacy laws like GDPR and HIPAA aren’t just rules on paper. They can shut you down or drain you in penalties.
Synthetic data avoids the mess entirely. You’re not anonymizing data or masking names; you’re generating entirely new records from scratch. No real people involved, no PII to slip through. You keep the patterns, lose the liability.
Some healthcare startups have already made this their default. They’re building diagnostic models without touching a single patient’s real medical file. In tightly regulated regions, it’s not just a good idea; it’s the only legal path forward.
When rare events break your model
You know the type, fraud attempts that happen once in a million transactions, machines that fail under just the right set of conditions, corner cases that confuse autonomous systems.
Good luck finding enough of those examples in your real dataset. And if you do? The sample size is so small, your model can’t learn anything from it.
Synthetic data changes that. You can generate hundreds, or thousands, of realistic versions of those rare cases, train your model on them, and finally get it to perform when it matters most.
When annotation at scale becomes a bottleneck
Anyone who’s tried annotating a massive dataset knows it’s brutal. Tedious. Expensive. And wildly inconsistent depending on who’s labeling it. You start small, then realize you're burning more budget on labeling than on actual model development.
This is where synthetic data flips the game. The data it generates is already labeled. Every frame, every token, every instance comes with metadata. No human tagging required. It cuts out the annotation loop entirely.
And if you’ve been down the path of scaling annotation before, this blog on large dataset annotation challenges hits the nail on the head. It’s exactly why more teams are turning to synthetic data instead.
When real data is too sensitive to touch
Say your dev team wants to build and test a new product feature. But the only real data you have is locked down, customer transactions, internal logs, or proprietary data with red flags all over it.
You can’t risk exposing it, even in a staging environment.
That’s where synthetic data steps in. You can simulate your production scenarios, load spikes, edge-case behavior, backend errors, without ever touching the real thing. Developers get full test coverage. Security teams sleep easy.
It’s not just safer, it’s how you move fast without cutting corners.
When your models learn the wrong things
Real-world data isn’t just messy; it’s biased. It reflects what’s already broken in the system: overrepresented groups, historical skew, missing context. If you feed that into your model as-is, you’re locking in those problems.
Synthetic data gives you control. You’re not stuck with whatever came through the pipeline. You can rebalance the dataset, inject fairness, test how the model behaves across different demographics, and fix gaps before they turn into real-world consequences.
Instead of inheriting the bias, you design around it. That’s the difference.
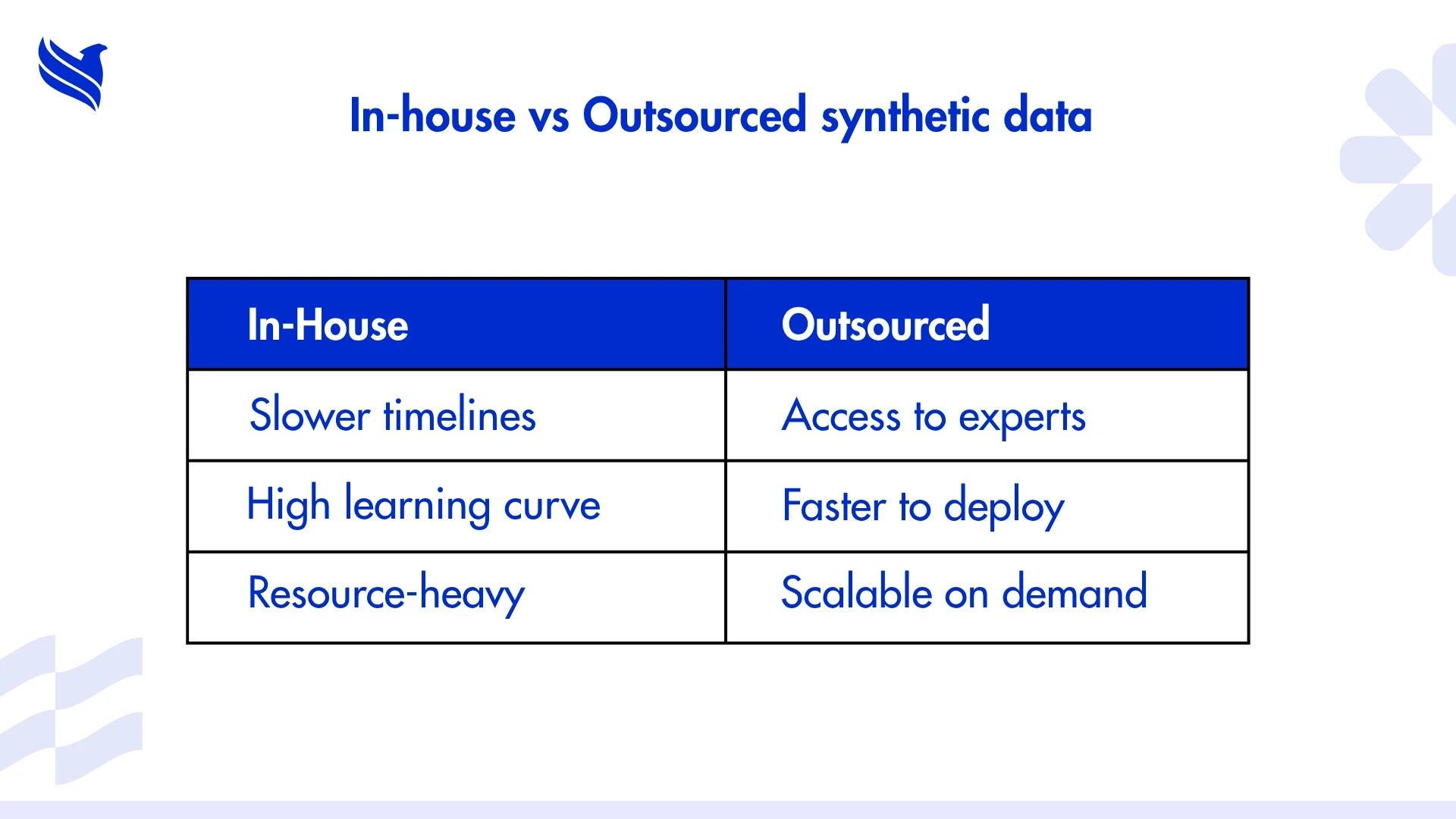
Here’s what most teams miss until they’re neck-deep in missed deadlines: generating synthetic data isn’t about pressing a few buttons on a tool and getting magic results. It’s real work, modeling your domain logic, simulating behavior, fine-tuning parameters, and running iterations until it behaves like the real thing. Then validating it over and over to make sure it holds up.
If that’s not your team’s day job, it’s going to slow everything else down.
And let’s be honest, most companies aren't built for this. Your engineers already have more on their plate than they can handle. Data scientists are pulled into 10 projects at once. You’re not going to build a synthetic data pipeline overnight without dropping the ball somewhere else.
This is exactly where outsourcing synthetic data generation services becomes less of a convenience and more of a necessity. Not to save money. But to save your timeline. To protect your team’s focus. To make sure you’re not quietly pushing half-baked data into a production model.
Outsourcing gets you:
And the biggest benefit? You free up your core team to work on what actually moves the needle, model logic, system behavior, architecture, not data scaffolding.
But here’s the catch: don’t just outsource to a vendor. Work with someone who understands your business. Financial models aren’t healthcare models. Retail data doesn’t behave like security logs. The partner needs to speak your language and get your use case before they generate a single row of data.
That’s how you get synthetic data that works. Not just synthetic data that “looks good.”
Here’s the mistake that haunts more ML teams than anything else: thinking the data alone will carry the model. No, it won’t.
You can spend weeks generating synthetic data, make it statistically perfect, design it to reflect every edge case, and still watch your model underperform. Why? Because your labels were wrong, or inconsistent, or just plain shallow.
Annotation is what makes the data useful. Without it, your model isn’t learning patterns; it’s memorizing noise. And that’s a hard lesson to learn once you’ve already gone to production.
Doesn’t matter if it’s synthetic or real data. Without the right labeling logic, it falls apart.
This is why your annotation workflow needs as much attention as your data pipeline. Skip it, rush it, or outsource it without oversight, and you’ll feel the hit in your metrics. And if you want a clear, real-world breakdown of why this matters, take five minutes to read how annotated data impacts AI accuracy in real-time apps. It’s not theoretical. It’s the difference between solid outputs and models that flinch in live settings.
Data is the structure. Labels are the message. Without both, you're building blind.
Let’s call it like it is: synthetic data is becoming essential for businesses serious about using AI in the real world.
It’s not about being trendy. It’s about being practical. You’re dealing with data that’s locked down, data that’s imbalanced, data that’s flat-out not enough. And you don’t have two years to wait around hoping it improves.
Synthetic data fixes problems that real data can’t, privacy concerns, edge cases, scalability, annotation fatigue, bias. This isn’t a backup plan. It’s the plan more teams are turning to because the old ways just don’t hold up.
Here’s the move: Keep your internal team focused on what only they can do, designing models, driving strategy, and delivering outcomes. Let a specialized partner take on the grind of generating synthetic data, validating it, and delivering it production-ready. That’s not cutting corners. That’s playing to strengths.
Need help generating the kind of synthetic data that actually drives results?
Talk to FBSPL. We help businesses build better training datasets, faster, without the legal noise, the annotation bottlenecks, or the budget black holes. Call today.
Insights and analysis from our industry experts.



